
Nvidia is riding high at the moment. The company has managed to increase the performance of its chips on AI tasks a thousandfold over the past 10 years, it’s raking in money, and it’s reportedly very hard to get your hands on its newest AI-accelerating GPU, the H100.
How did Nvidia get here? The company’s chief scientist, Bill Dally, managed to sum it all up in a single slide during his keynote address to the IEEE’s Hot Chips 2023 symposium in Silicon Valley on high-performance microprocessors last week. Moore’s Law was a surprisingly small part of Nvidia’s magic and new number formats a very large part. Put it all together and you get what Dally called Huang’s Law (for Nvidia CEO Jensen Huang).
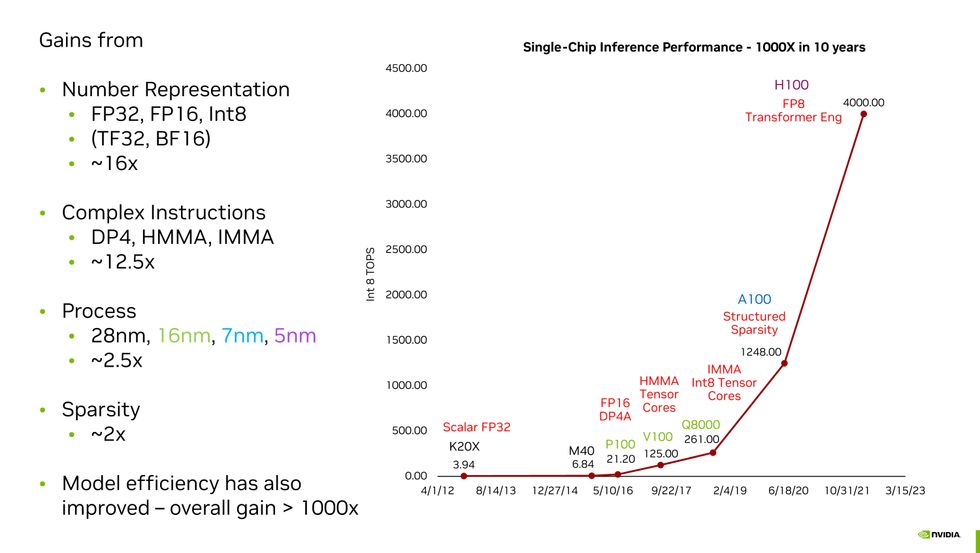 Nvidia chief scientist Bill Dally summed up how Nvidia has boosted the performance of its GPUs on AI tasks a thousandfold over 10 years.Nvidia
Nvidia chief scientist Bill Dally summed up how Nvidia has boosted the performance of its GPUs on AI tasks a thousandfold over 10 years.Nvidia
Number Representation: 16x
“By and large, the biggest gain we got was from better number representation,” Dally told engineers. These numbers represent the key parameters of a neural network. One such parameter is weights—the strength of neuron-to-neuron connections in a model—and another is activations—what you multiply the sum of the weighted input at the neuron to determine if it activates, propagating information to the next layer. Before the P100, Nvidia GPUs represented those weights using single precision floating-point numerals. Defined by the IEEE 754 standard, these are 32 bits long, with 23 bits representing a fraction, 8 bits acting essentially as an exponent applied to the fraction, and one bit for the number’s sign.
But machine-learning researchers were quickly learning that in many calculations, they could use less precise numbers and their neural network would still come up with answers that were just as accurate. The clear advantage of doing this is that the logic that does machine learning’s key computation—multiply and accumulate—can be made faster, smaller, and more efficient if they need to process fewer bits. (The energy needed for multiplication is proportional to the square of the number of bits, Dally explained.) So, with the P100, Nvidia cut that number in half, using FP16. Google even came up with its own version called bfloat16. (The difference is in the relative number of fraction bits, which give you precision, and exponent bits, which give you range. Bfloat16 has the same number of range bits as FP32, so it’s easier to switch back and forth between the two formats.)
Fast forward to today, and Nvidia’s leading GPU, the H100, can do certain parts of massive-transformer neural networks, like ChatGPT and other large language models, using 8-bit numbers. Nvidia did find, however, that it’s not a one-size-fits-all solution. Nvidia’s Hopper GPU architecture, for example, actually computes using two different FP8 formats, one with slightly more accuracy, the other with slightly more range. Nvidia’s special sauce is in knowing when to use which format.
Dally and his team have all sorts of interesting ideas for squeezing more AI out of even fewer bits. And it’s clear the floating-point system isn’t ideal. One of the main problems is that floating-point accuracy is pretty consistent no matter how big or small the number. But the parameters for neural networks don’t make use of big numbers, they’re clustered right around zero. So, Nvidia’s R&D focus is finding efficient ways to represent numbers so they are more accurate near zero.
Complex Instructions: 12.5x
“The overhead of fetching and decoding an instruction is many times that of doing a simple arithmetic operation,” said Dally. He pointed out one type of multiplication, which had an overhead that consumed a full 20 times the 1.5 picojoules used to do the math itself. By architecting its GPUs to perform big computations in a single instruction rather than a sequence of them, Nvidia made some huge gains. There’s still overhead, Dally said, but with complex instructions, it’s amortized over more math. For example, the complex instruction integer matrix multiply and accumulate (IMMA) has an overhead that’s just 16 percent of the energy cost of the math.
Moore’s Law: 2.5x
Maintaining the progress of Moore’s Law is the subject of billons and billions of dollars of investment, some very complex engineering, and a bunch of international angst. But it’s only responsible for a fraction of Nvidia’s GPU gains. The company has consistently made use of the most advanced manufacturing technology available; the H100 is made with TSMC’s N5 (5-nanometer) process and the chip foundry only began initial production of its next generation N3 in late 2022.
Sparsity: 2x
After training, there are many neurons in a neural network that may as well not have been there in the first place. For some networks, “you can prune out half or more of the neurons and lose no accuracy,” said Dally. Their weight values are zero, or really close to it; so they just don’t contribute the output, and including them in computations is a waste of time and energy.
Making these networks “sparse“ to reduce the computational load is tricky business. But with the A100, the H100’s predecessor, Nvidia introduced what it calls structured sparsity. It’s hardware that can force two out of every four possible pruning events to happen, leading to a new smaller matrix computation.
“We’re not done with sparsity,” Dally said. “We need to do something with activations and can have greater sparsity in weights as well.”
From Your Site Articles
Related Articles Around the Web